|
| Où en est Leela ? par ins12537 le
[Aller à la fin] |
| Informatique | |
Bonjour à tous,
Leela continu jour après jour à progresser et commencent à gagner quelques parties contre des modules évalués dans les 3000 Elo.
Encore beaucoup de grosses gaffes et des prises de risque qui ne sont pas toujours payantes, des tentatives de forcer le gain qui se terminent par des défaites mais aussi des parties qui me semblent magnifiques dans un style qui fait penser à celui du grand frère AlphaZero.
Je lui fait faire des matches de 6 parties en 10mn+10s, actuellement contre Critter 0.90. Il (ou elle ?) ne gagne pas encore souvent mais il y a du bon.
https://lichess.org/jAvrnx4x#0
A noter qu'après avoir longtemps joué 1.e4 (Leela joue sans bibliothèque d'ouvertures) c'est depuis peu 1.d4 qui a la préférence.
Au rythme de progression actuel Leela pourrait à mon avis parfaitement être utilisé par les meilleurs GMI, essentiellement pour trouver de nouvelles idées.
|
|
|
Il faudrait davantage de contributeurs pour accélérer la génération des nouveaux ID.
Ce serait bien de remonter vers les 200 000 parties/jour.
|
|
|
Bonjour,
Comment fait-on pour contribuer à faire progresser Leela ?
|
|
|
Si tu comprends l'anglais, tu as la page principale ici :
https://github.com/glinscott/leela-chess/wiki
Tu peux utiliser ton processeur et/ou ta carte graphique pour faire des parties d'entrainement en téléchargeant cpu-win.zip ou gpu-win.zip (si tu as une bonne carte graphique, le gpu devrait générer plus de parties que le cpu)
https://github.com/glinscott/leela-chess/releases
Tu peux ne pas utiliser les ressources de ton pc en utilisant google Colab (il faut avoir une adresse gmail). C'est ce que je fais
https://github.com/glinscott/leela-chess/wiki/Run-Leela-Chess-Zero-client-on-a-Tesla-K80-GPU-for-free-(Google-Colaboratory)
Leela a besoin de contributeurs pour lui faire
jouer des matchs d'entrainement.
Dans le cas du Google Colab, ma connexion internet n'est pas du tout ralenti.
Si tu n'as rien compris de ce que je viens d'écrire, je peux être plus précis ^^
|
|
|
Non, c'est bon, j'ai compris, merci beaucoup pour les infos mop ! Je testerai ça ce soir
|
|
|
Un match de 6 parties contre Critter 0.90a, à vous de juger. Network 350.
https://lichess.org/evGMC6o0
https://lichess.org/HFxxkETj
https://lichess.org/4cB8tBo0
https://lichess.org/oWRULZqD
https://lichess.org/tkZweW2l
https://lichess.org/unkeMeLD
|
|
|
Longue période stagnation du niveau, Leela a-t-elle atteint ses limites ?
Assez curieusement elle joue maintenant 1.c4.
Elle semble dominer positionnellement ses adversaires mais en mode Kasparov, c'est à dire de façon extrêmement active, n'hésitant pas à jouer des sacrifices positionnels. Ses défaites sont essentiellement dues à des gaffes, de vraies gaffes comme un humain peut les faire parce qu'elle a du mal à voir les tactiques basées sur des sacrifices. On l'a même vu rater un mat en 2 qui commençait par un sacrifice de Dame.
|
|
|
chess.com se lance dans la bataille en rachetant Komodo pour en faire un module basé sur l'IA. https://www.chess.com/fr/news/view/chess-com-rachete-komodo-et-lance-une-nouvelle-version-monte-carlo-similaire-a-alphazero
|
|
|
Après un long passage à vide du à un problème dans la gestion de la règle des 50 coups (dans une position inférieure mais sur le point d'atteindre le 50ème coup on pouvait voir Leela donner une pièce pour perdre plutôt que d'annuler) Leela vient de retrouver son meilleur niveau avec des parties toujours spectaculaires.
Je vous en remet une contre Houdini 1.5, un module qui tourne peut-être à 3000 Elo. L'art de sacrifier un pion quand on en a déjà 2 de retard.
On notera quand même 14.f3? une gaffe typique de Leela qui n'a pas envisagé le sacrifice Fxf3.
https://lichess.org/1XE0Dgq6
|
|
|
Houdini 1.5 date de 2010.
La version actuelle est la 6!
|
|
|
Mais puisqu'on te dit qu'il vaut 3000 élos ! Bon il perd avec une pose écrasante mais c'est parce que Leela à joué une partie spectaculaire ! Assieds-toi et profite un peu, oh !
|
|
|
@lefouduroi je sais mais il est plus intéressant de voir les progrès contre un module qui a à peu près son niveau que contre SF9 ou Houdini 6 qui gagneraient 90% des parties (et en plus Houdini 1.5 est gratuit, pas la version 6)
N'en déplaise au pisse-vinaigre de service l'évaluation du niveau d'Houdini 1.5 est donnée sur la page http://www.computerchess.org.uk/ccrl/4040/cgi/engine_details.cgi?print=Details&each_game=1&eng=Houdini%201.5a%2064-bit#Houdini_1_5a_64-bit.
Ca vaut ce que ça vaut mais ça permet de situer Leela par rapport aux autres.
De plus la partie s'est jouée en 10mn+10s et mon ordi n'est pas surpuissant donc le niveau max n'est pas atteint mais à la même cadence ces modules explosent n'importe quel GMI.
Oui revenir ainsi d'une gaffe contre un module c'est spectaculaire, obtenir une position favorable avec 2 pions de retard en en sacrifiant un 3ème c'est spectaculaire. Surtout que ce genre de partie n'a rien d'exceptionnel, Leela en produit à la pelle. Quand on considère que le module apprend par lui-même, qu'il découvre tous les principes de jeu de lui-même (personne n'a été lui dire qu'une Tour est généralement plus forte qu'un Cavalier) on comprend (enfin, ceux qui peuvent) qu'une nouvelle compréhension du jeu est en train d'émerger.
|
|
|
Je ne sais pas comment tu fais pour débiter autant d'âneries à la minute : tu es épuisant. Si tu cites une source apprend à le faire correctement (la FAQ est là pour t'aider si tu ne sais pas faire un simple lien cliquable, monsieur l'informaticien) et surtout lis avant de t'exprimer. Tu peux trouver ici (http://www.computerchess.org.uk/ccrl/4040/about.html) les conditions du test qui n'ont rien à voir avec ce que tu fais sur ta brouette. De plus regarder la partie permet de comprendre assez vite que ce n'est pas le meilleur niveau d'Houdini même s'il faut pour cela quelques compétences échiquéennes.
Pour comprendre en quoi cela affecte le niveau de jeu du module il faut comprendre comment il fonctionne. Les modules classiques évaluent une position à une profondeur donnée : ils ne raisonnent pas en termes d'attaque, défense ou ce que tu veux. C'est une évaluation clinique de la position et la profondeur joue un rôle primordial. Pour caricaturer si j'ai un sacrifice de Dame qui mate en 12 mais avec une série de coups uniques, que tous les autres coups donnent l'avantage à l’adversaire et que le module calcule jusqu'à une profondeur de 11 coups et demi (p=23) et bien il considérera le sacrifice de Dame comme incorrect. C'est pourquoi il faut laisser tourner le module longtemps pour obtenir une profondeur suffisante et avoir un avis "fiable".
Alphazéro (et ses dérivés) n'ont pas changé cette méthode d'évaluation et de calcul ils n'ont juste pas de règles humaines implémentées pour écourter l'arbre de calcul. (Du genre : ne donne pas une Tour contre un Cavalier, sauf si tu as vu un gain d'au moins 1.5, etc.) Le nouveau module apprend par renforcement : il regarde dans les parties faites contre les adversaires ce qui a le mieux marché et décide de l'utiliser. La claque qu'Alphazéro à foutu à Stockfish n'est en rien précurseur d'une nouvelle façon de réfléchir : elle révèle juste deux choses. Premièrement le calcul pur semble plus fort (ou plus efficace) que le calcul pondéré par des principes humains (mais ceux ayant quelques connaissances en informatique s'en doutaient déjà avant...) et deuxièmement, ce qui est sans doute le plus intéressant, les anciens modules sont vulnérables et particulièrement sur les sacrifices contre de l'activité. Ils sont limités par leur profondeur de calcul et n'arrivent pas à "sentir" que leur position va se dégrader s'ils encaissent le matériel donc ils l'encaissent et s'inclinent sur le long terme. Il n'y a pas de conception profonde ou quoi que ce soit là dedans, juste de l’empirisme et du pragmatisme de haut-niveau : le nouveau module choisit ce qui lui donne les meilleures chances de gain.
Le reste c'est un joli coup de com de Google : le module nouveau est arrivé, il est gouleyant et sent la banane...
On peut espérer que cela redonnera de l'espoir à tous les joueurs de voir que les modules ne sont pas infaillibles et qu'il est encore possible de dépasser leur évaluation mais nous sommes très loin de ta révolution.
Désolé d'avoir argumenté, je te résume : XxxX XxxxXxx xXXXxx XXXxxXXX
|
|
|
" ils ne raisonnent pas en termes d'attaque, défense ou ce que tu veux"
Ah bon ????????…. attends, il n'y en a pas encore assez ??????????????
"si j'ai un sacrifice de Dame qui mate en 12 mais avec une série de coups uniques, que tous les autres coups donnent l'avantage à l’adversaire et que le module calcule jusqu'à une profondeur de 11 coups et demi (p=23) et bien il considérera le sacrifice de Dame comme incorrect."
Vous en êtes encore là et venez donner des leçons ? Ca me fait bien rire.
|
|
|
1- Décide-toi entre le tutoiement et le vouvoiement : ça fait désordre.
2- Si tu me cites, fais-le correctement : tu as oublié le début de la phrase qui n'était pas là par hasard : "Pour caricaturer..."
3- Si d'après toi j'ai tort, peux-tu m'expliquer les brusques sauts d'évaluation dans les finales par exemple ? A défaut pourrais-je avoir une explication de comment fonctionne un module selon toi ?
|
|
|
L'algorithme Alpha-Beta utilisé par les modules classiques je connais, je m'y étais intéressé il y a peut-être 30 ans. Il s'agit en gros de parcourir l'arbre des coups avec le principe qu'il est inutile de poursuivre l'analyse d'une branche à partir du moment où on a une réfutation, c'est ce qui évite de tout parcourir. On donne une note à chaque position en fonction de différents critères qui permettent de l'évaluer, le pus important étant bien sûr le matériel. On analyse de plus en plus loin mais il devient vite évident au développeur qu'il ne peut s'arrêter à une profondeur donnée pour évaluer la valeur d'une variante. Tout simplement parce que si le dernier coup analysé est par exemple la prise d'une pièce la variante peut sembler excellente en oubliant que le coup suivant serait la perte d'une pièce plus importante.
Donc non, un module ne s'arrête pas à la profondeur qu'il indique, ça c'est juste la profondeur jusqu'où il a fait une analyse fine. Bien sûr il y a un moment où il doit s'arrêter et il ne peut pas tout voir ce qui explique ses changements d'évaluation.
Je ne sais pas exactement comment fonctionnent les modules qui utilisent Monte-Carlo (AlphaZero, LeelaZero, Komodo Monte-Carlo...). Je sais juste ce qu'en a dit la presse, c'est à dire qu'on leur a appris les règles et qu'ils sont capables d'accumuler des connaissances pour découvrir comment gagner et progresser.
Avec un module Alpha-Béta c'est le développeur qui programme la fonction de calcul de l'évaluation d'une position. C'est le développeur qui fixe par exemple les valeurs relatives des pièces ou la valeur de telle ou telle structure de pion, ou l'importance d'une colonne ouverte, etc. Ca ce sont des notions qui viennent des connaissances humaines empiriques sur les échecs, l'ordi ne découvre rien, il utilise seulement au mieux ce que nous savons déjà.
Avec un module Monte-Carlo c'est l'ordinateur qui découvre tout, il va donc avoir une compréhension du jeu qui n'a rien à voir avec les connaissances humaines et c'est ce qui va nous apporter de nouvelles connaissances sur le jeu.
|
|
|
Ça n'a rien de révolutionnaire, ça existe depuis au moins 2009:
Rybka's Monte Carlo analysis
|
|
|
Bonjour
tu confonds JLuc74.
Un brute force (avec elagage ou pas) et un MC (ou une version plus élaborée comme un AG) fonctionne strictement du même principe :
- simulation
- evaluation
là, on parle d'apprentissage. Il n'y a plus ce cycle.
je m'étais intéressé à Alpha quand il apprenait le go. Google n'est pas fou ; Alpha ne fait pas que de l'apprentissage, il fait aussi de la simu (par du MCTS) et de l'évaluation.
Cela lui permet d'apprendre beaucoup plus vite et surtout de "vérifier" a priori des erreurs.
Il n'a pas besoin d'avoir un moteur de simu et d'évaluation très performants vu qu'il va gommer ces défauts au fur et à mesure de son apprentissage.
de ce que j'en lit, Leela ne fait pas de simu ? c'est dommage. ça bootstrap énormément son apprentissage.
Inversement, lorsque les modules classiques commenceront à apprendre, la performance de leur moteur leur permettra d'apprendre plus rapidement et de vérifier de façon encore plus pertinente.
pour ceux qui aiment coder ce type d'algorithme, il existe un site sur lequel il y a des compétitions régulièrement de "bots" (je n'appelle pas cela des IAs) ; codingame.com
beaucoup d'algo génétique, de Monte-Carlo ou de MiniMax. Même des heuristiques peuvent parfois tirer leur épingle du jeu.
Le jeu d'échecs n'est pas présent, mais beaucoup de jeux en 1v1 y sont présents (jeu de dommination comme le go ou tactique comme le corridor, ...)
|
|
|
@JLuc : un brute force (je pique le terme à hberger : il est parlant) simule les suites possibles de la partie créant par là-même un arbre des coups possibles et leur attribue à chacun une évaluation. Il choisit ensuite le coup ayant la meilleure évaluation. Son choix est donc principalement basé sur son calcul (sa fonction de simulation et sa fonction d'évaluation) et est d'autant plus précis qu'il a de temps pour parcourir l'arbre. C'est pourquoi quand tu veux handicaper un module tu l'obliges à jouer plus vite, c'est pourquoi tous les secondants des forts joueurs ont des gros PC et les laissent tourner des nuits entières, c'est pourquoi crier au scandale dès qu'un Top GM joue un coup faisant descendre légèrement la barre d'évaluation de chessbomb est ridicule car le module est en profondeur 20, c'est pourquoi Rybka (profondeur moyenne entre 15 et 20 coups) a supplanté Fritz (profondeur moyenne 15 coups) avant de se faire bouffer par Houdini (profondeur moyenne entre 20 et 25 coups) qui lui même s'est fait détrôné par Stockfish (actuellement profondeur moyenne aux alentours des 30 coups), c'est pourquoi les modules actuels donnent toujours un gros avantage aux Blancs dans l'Est-Indienne, etc.
Amener l'élagage dans le débat ne change pas la façon de fonctionner de ces modules : l'élagage permet de réduire le temps nécessaire pour examiner tous les coups de l'arbre afin d'atteindre une profondeur plus importante plus rapidement. Avec un brute force la profondeur est la clé ! D'ailleurs mon exemple sur le sacrifice de Dame illustre parfaitement cela : tant que le module n'a pas atteint la profondeur nécessaire pour voir le gain il dégagera la variante car il y aura, selon toi, une réfutation, la perte de la Dame.
Les modules Alpha basent leurs choix sur leurs expériences : si j'ai battu un adversaire avec tels coups alors je peux le rejouer, jusqu'à ce que mes résultats ne soient plus intéressants. (Là encore je schématise) Ils sont donc parfaits pour s'adapter à un adversaire spécifique et le déboîter (cf. la claque mise à SF, bridé il faut le rappeler).
|
|
|
Je te trouve bien assertif @SLM.
Es-tu bien sûr de l'assertion "Alphazéro (et ses dérivés) n'ont pas changé cette méthode d'évaluation et de calcul ils n'ont juste pas de règles humaines implémentées pour écourter l'arbre de calcul." Au contraire, comme je comprends les choses, c'est justement le principe du deep reinforcement learning d'utiliser un réseau de neurone pour obtenir une meilleure approximation de cette méthode d'évaluation (appelée classiquement "reward" en RL).
Je pense qu'on est tous d'accord sur le coup de com de google, mais affirmer : "La claque qu'Alphazéro à foutu à Stockfish n'est en rien précurseur d'une nouvelle façon de réfléchir" semble un petit peu fort. Si on admet qu'AlphaZéro et AlphaGoZéro sont basé sur les mêmes principes, AlphaGoZéro semble tout de même être basé sur un paradigme très différent de celui du calcule brut "classique".
@hberger peux-tu donner la référence de "ce que j'en lit, Leela ne fait pas de simu" (article ou site) ? Car si c'est le cas, je doute qu'on puisse appelé ça du reinforcement learning.
|
|
|
Mea culpa pour les assertions mais je t'invite à resituer mes interventions dans le contexte : je vois passer un bon gros paquet d'inepties échiquéennes et informatiques assénées par le Icare des pendules, je m’adapte au niveau. ;-)
A te lire je découvre un sens non désiré à ma formulation "cette méthode". J'entendais rappeler que prétendre qu'Alpha réfléchit complètement différemment des autres modules est faux. L'idée principale reste la création d'un arbre de variantes puis l'évaluation de ces variantes et enfin un choix basé sur cette évaluation. (et un peu d'aléatoire au début mais plus il apprend moins c'est le cas) Ce qui est intéressant (et modifié par rapport aux modules classiques) c'est le processus de priorisation des coups à évaluer (on se rapproche effectivement de l'humain) mais surtout l'évaluation en elle-même qui n'est plus basée sur un calcul mais sur la proba de gain. Je ne voulais en rien signifier que la fonction d'évaluation était la même chez les deux modules.
Enfin la claque foutue par Alpha à SF pourrait être précurseur d'une nouvelle façon de réfléchir mais ne l'est pas à mon sens car Alpha a pu jouer des parties d'entraînement contre SF avant le match et c'est là toute la différence. Alpha a appris les points faibles de Sf (comme cité plus haut : le matérialisme si cher à nos modules contemporains) puis les a exploité. Un peu de lecture si le cœur t'en dit : https://medcraveonline.com/OAJMTP/OAJMTP-01-00005.pdf
|
|
|
Voilà comment est présenté Komodo 12 :
Le système "Monte-Carlo" de Komodo 12 se comporte différemment d'un module normal : en peu de temps il joue toute une série de parties contre lui-même et arrive à des évaluations basées sur les résultats de ces parties. Pour ce qui est de la force, la version "Monte-Carlo" n'est pas encore au niveau de Komodo 12 classique. Mais ce qui est intéressant, c'est que le style de jeu des deux versions diffère nettement. Le GM Larry Kaufman explique : « Ce nouveau moteur a le comportement caractéristique d'AlphaZero en ce qu'il est moins matérialiste, plus agressif et plus humain que les moteurs normaux. Le style de jeu de Komodo "Monte-Carlo" est beaucoup plus audacieux que celui d'un moteur ordinaire. Il préfère l'activité au matériel dans la mesure du raisonnable. »
|
|
|
Le style de jeu de Komodo "Monte-Carlo" est beaucoup plus audacieux que celui d'un moteur ordinaire. Il préfère l'activité au matériel dans la mesure du raisonnable. »
Eh oui, le matériel n'est-il pas, simplement, le substitut à notre incapacité (provisoire ?) de calculer toute l'activité ?
|
|
|
@qbe
tu m'as mis un doute, du coup, j'ai regardé le code de Leela.
Effectivement, il simule et évalue sur un UCT (équivalent d'un MCTS).
AlphaZero, à ce que j'ai lu (pas pu voir le code, hélas :-) ) est différent de Leela.
Il faut bien comprendre que, dans la logique d'une simulation / évaluation (que ce soit brute force ou Monte-Carlo), il y a un GROS défaut dans la cuirasse, c'est l'évaluation de la position obtenue.
Déja, des évaluations humaines sur la position en cours peuvent être différentes selon les GMIs et leur style, et en plus, les développeurs ne peuvent interpréter sous format heuristique ces subtils différences.
Bref, Alpha sort complètement de ce shéma là puisque l'objectif est de complètement s'abstraire de la partie évaluation en ayant plutot comme critère : "houla, cette position, je la connais, elle me dit quelque chose, attends que je me souvienne ... oui, elle est gagnante à 75% des cas".
En clair, de ce que je lis, pour moi, un Komodo bruteforce classique ou un MCTS, c'est pareil de mon point de vue. Je pense même que le MCTS n'arrivera pas à battre le bruteforce car les limites de la fonction d'évaluation de la position va nécessiter de vraiment parcourir tout l'arbre pour "assurer" ou alors avoir une profondeur du MCTS tellement supérieure au brute-force ...
Alpha, ce n'est pas pareil. par contre, Alpha a un inconvénient en jouant contre un seul et même adversaire; c'est la super-spécialisation.
Mais je ne vois pas comment on pourrait utiliser cet inconvénient pour le battre.
Quoiqu'il en soit, pour nous, développeurs, le jeu d'échecs n'a plus d'intérêt.
Seuls des jeux avec un branching factor plus important ont encore un sens.
La victoire d'Alpha en go,a eu NETTEMENT plus d'impact en IA que la victoire de DeepBlue contre Kasparov qui était plus médiatique mais moins intéressante.
Et même là, je comprends Google et sa volonté d'utiliser Alpha sur d'autres domaines que le jeu ; il en a, hélas, fait le tour.
Maintenant, la seule question, en temps que joueur d'échecs, serait de savoir si le jeu d'échecs peut être résolu (même une résolution ultra-faible) et quel serait le ELO d'un programme parfait, mais ces questions n'ont aucun intérêt pour des développeur en IA, que pour nous, pauvres mazettes d'échecs.
|
|
|
C'est clair que l'activité, je dirais même l'agressivité positionnelle est ce qui caractérise ces modules. Quand ça veut bien marcher ça donne des parties très intéressantes.
Pour nous, joueurs d'échecs, ça peut ouvrir des portes parce que ça remet en cause pas mal de dogmes sclérosants. Disons que c'est plutôt inspirant. Ce qui me surprend par exemple c'est l'importance que Leela donne au pions avancés en 6ème rangée et la façon dont elle les exploite.
|
|
|
pas surprenant.
A évaluation équivalente (matérialiste), une profondeur plus grande va forcément engendrer un jeu plus stratégique et plus "long-terme".
Ce n'est pas le type d'algorithme qui engendre cet effet (enfin, pas directement), c'est la profondeur.
Après, cet effet peut aussi être créé par une évaluation différente (pour cela que des progs "classiques" avec une même profondeur jouent de façon différente).
Sachant que l'effet de l'évaluation est amplifiée par l'élagage ...
|
|
|
La profondeur n'y change rien, pour le même temps Leela aurait plutôt tendance à voir moins loin, c'est du moins ce qu'indique le module.
L'élagage par contre c'est autre chose, pour une même profondeur le nombre de coups analysés par Leela est peut-être 20.000 fois moins important que pour un module traditionnel.
Je fais jouer des parties en 10mn+10s. Habituellement Leela est à une profondeur entre 18 et 20 pour 2000 coups analysés contre une même profondeur et quelques 50.000.000 coups analysés pour un module classique. Evidemment ça explique les lacunes tactiques de Leela qui n'envisage pas nombre de sacrifices tout en parvenant cependant à gagner un certain nombre de parties.
|
|
|
L'élo du prog parfait dépendra du style, s'il ne joue que des slaves d'échange on doit pouvoir tirer quelques nulles...
|
|
|
JLuc74 : ce n'est justement pas la même profondeur, puisqu'il n'y a pas d'évaluation a proprement parlé, mais il y a "pondération" par rapport à son apprentissage.
il faut le voir comme une profondeur "infinie".
Comme je l'ai dis précédemment ; cette pondération est aussi utilisé pour élaguer ; la bibliothèquee et la pertinence des parties jouées lors de l'apprentissage (et la phase de RL) a une vraie valeur ; c'est sa qualité qui fait office de moteur d'évaluation.
Bref, autant j'aime bien les échecs, j'aime bien l'IA ; autant je ne me passionne plus du tout dans le domaine des IAs aux échecs.
|
|
|
Mouais je suis pas convaincu sur quelques unes de mes parties, je me suis fait torcher sauf lorsque j'ai joué d4+c4 et qu'il a transposé dans une Nimzo. Voilà comment j'ai gagné la dame (j'avais les Blancs
1. d4 Nf6
2. c4 e6
3. Nf3 d5
4. Nc3 Bb4
5. e3 O-O
6. Bd3 dxc4
7. Bxc4 c5
8. O-O cxd4
9. exd4 b6
10. Re1 Bb7
11. Ne5 Nc6
12. Nxc6 Bxc6
13. Bg5 h6
14. Bh4 Rc8
15. Bd3 Qxd4
16. Bh7+ Kxh7
17. Qxd4
Et ça en mode "hard" (400 nodes). J'ai pas d'explication sur une telle bourde. Bon après j'ai super mal joué et il a réussi à revenir mais c'est pas la question.
|
|
|
Une bourde classique de Leela qui n'envisage pas les sacrifices. Une grande partie de ses défaites sont liées à des gaffes de ce genre. A côté de ça le module gagne régulièrement contre de modules à la force reconnue.
|
|
|
Leela (ou Lc0) est maintenant à un niveau très compétitif, probablement top 2 dans le tournoi TCEC qui regroupe tous les meilleurs programmes.
De plus comme alpha0, elle développe un jeu fascinant, presque humain, très stratégique, on a l'impression de le comprendre.
Sa marque de fabrique est la restriction voire l'emprisonnement des fous adverses. Voici un exemple de diagramme tiré du tournoi mentionné ci-dessus, contre Fire, un des 8 meilleurs modules actuels (ronde 24.3) !
Son jeu est très impressionnant dans l'ouverture et le début du milieu de jeu. L'évaluation des finales en revanche est encore loin de celle de Stockfish, ce qui fait que la transition milieu de jeu/finale l'amène parfois à des positions qu'elle évalue comme prometteuse mais qui sont nulles en fait (ce que Stockfish voi très bien).
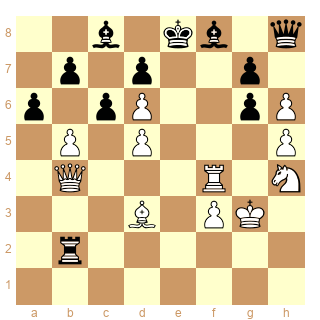
|
|
|
Leela a sorti une nouveauté théorique sur la Nimzo
1 d4 Cf6
2 c4 e6
3 Cc3 Fb4
4 e3 00
5 Fd3 b6
6 e4 Fb7
7 e5 Fxg2
8 exf6
l'idée est
si 8...Dxf6 9 Dg4 menace le fou en g2 et gagner la dame après Fg5
quand on pense que de nombreux débutants ont abandonné au 8 ème coup, dans une position gagnante
|
|
|
intéressant en effet ! et sur 8...g6 suivi de 9...Fxh1 que fait-on ?
|
|
|
c'est la suite de la partie, en notation anglaise
1. d4 Nf6 2. c4 e6 3. Nc3 Bb4 4. e3 O-O 5. Bd3 { E47 Nimzo-Indian Defense: Normal Variation, Bishop Attack } b6 6. e4 Bb7 7. e5 Bxg2 8. exf6 g6 9. Bg5 Bxh1 10. Qg4 d5 11. Qh4 Nd7 12. f3 Rb8 13. Kf2 dxc4 14. Be4 c5 15. Bxg6 hxg6 16. Ne4 Bd2 17. Bxd2 cxd4 18. Bg5 Qc7 19. Qh6 Qxh2+ 20. Qxh2 Ne5
ça continue
|
|
|
une video
https://www.youtube.com/watch?v=0Hhhpu2_Ugk&t=18s
|
|
|
merci !
|
|
|
Je me demande combien de nouveautés théoriques vont sortir suite aux trouvailles de Leela, AlphaZero et quelques autres...
|
|
|
Nouveauté dans cette position mais une idée déjà connue il y a au moins 10 ans avec c5 a3 Fxc3 bxc3 en plus.
Voir la partie sur FE
[Event "Nancy (c tournament)"]
[Site "?"]
[Date "2009.02.??"]
[Round "4"]
[White "Brethes, François"]
[Black "Iglesias, Joachim"]
[Result "1/2-1/2"]
[ECO "E28"]
[PlyCount "67"]
[EventDate "2009.??.??"]
1. d4 Nf6 2. c4 e6 3. Nc3 Bb4 4. e3 ({JE: If White adopts the traditional
Sämisch move order, Black can delay castling and play the early ...b6 idea
without fearing e4:} 4. a3 Bxc3+ 5. bxc3 c5 6. e3 b6 7. Bd3 Bb7 8. f3 Nc6 9.
Ne2 O-O {and Black has managed to get what he wants (this line is covered in
Geller-Euwe, Zürich 1953, and also a Sämisch survey on 4 a3 Bxc3+ 5 bxc3 b6 6
e3).}) 4... c5 5. Bd3 O-O ({JE: Of course Black could play} 5... b6 {
here, but White is under no obligation to reply with 6 a3!}) 6. a3 Bxc3+ 7.
bxc3 b6 ({JE:} 7... Nc6 {is the main line.}) 8. e4 {
JE: This is certainly an interesting attempt to exploit Black's move order.} (
8. Ne2 {has been the most common move, and here} Bb7 9. f3 {
transposes to the note on 4 a3.} ({White could also play} 9. O-O {
planning to answer} Nc6 10. e4 {so Black might be better off with 9...d6.}))
8... Bb7 (8... Ne8 {9 Ne2 Nc6 returns the main line of the Sämisch, but again
White isn't forced to play this way. For example there's 9 Qh5!?or} 9. Nf3 {
which led to a nice win for White in Shcherbakov-Levit, Leningrad 1955:} Nc6
10. e5 f5 11. d5 Na5 12. Bg5 Qc7 13. d6 Qc6 14. Be7 Rf7 15. Ng5 Qxg2 16. Qh5 g6
17. Qh6 Qxh1+ 18. Ke2 Qg2 ({Black had to play} 18... Qxa1 19. Nxf7 Ng7 20. Ng5
Qb2+ 21. Kf1 Qc1+ 22. Kg2 Bb7+ 23. Kh3 Qxg5) 19. Nxf7 Ng7 20. h3 f4 21. Ng5 f3+
22. Ke1 {and 1-0.}) 9. e5 (9. f3 Ne8 10. Ne2 Nc6 11. O-O {
again brings us back to lines we can reach after 4 a3.}) (9. Bg5 h6 10. h4 {
is another dangerous idea for Black to face, and certainly} d6 11. e5 dxe5 12.
dxe5 Be4 13. Rh3 {
left him with some problems to solve in Keres-Reshevsky, Zürich 1953.} Bxd3 14.
Rxd3 Qc7 {and here 15 Bxf6 was Keres's choice, but in a later game} 15. exf6
hxg5 16. hxg5 Qe5+ 17. Kf1 Qxg5 18. fxg7 {
left White with an obvious advantage (Popov-Carosi, correspondence 1972).})
9... Bxg2 (9... Ne8) 10. Bg5 (10. exf6 {sets a little trap:} Bxh1 (10... Qxf6
11. Qg4 {- with the threats of both Bg5 and Qxg2 -} Bxh1 12. Bg5 h5 13. Qh4 {
wins the queen}) (10... g6 11. Bg5 {transposes to the game}) 11. Bxh7+ (11.
fxg7) 11... Kxh7 12. Qh5+ Kg8 13. fxg7 f6 14. gxf8=Q+ Qxf8 {
and White has at least a draw by perpetual.}) 10... Bxh1 11. exf6 g6 12. Bxg6 {
The only way!} (12. Qg4 h5) 12... hxg6 ({After} 12... fxg6 13. f7+ Kxf7 14.
Bxd8 Rxd8 {White can win the h1 bishop:} 15. f3 Rf8 16. Kf2 Kg8 17. Kg3 {
with the idea of h3 and Kh2.}) 13. Qg4 {The first key position of the game:
Black is a rook up but has to find something against the simple threat of
Qh4-Qh6.} d5 (13... Na6 {to reach the e8-square was an alternative but it
looks more dangerous for Black with the closed centre.} 14. Qh4 Nc7 15. Rd1 (
15. Bh6 {is the computer's choice but this cannot be good for White:} Ne8 16.
Bxf8 Qxf6 17. Qxf6 Nxf6 18. Be7 Kg7 19. f3 Rh8 20. Bd6 g5 21. Kf2 g4) 15... Ne8
16. Rd3 Bg2 17. Rg3 Nd6 18. Rxg2 Nf5 (18... cxd4 19. Qh3 dxc3 20. Rg4 c2 21.
Ne2 Nf5 22. Rh4) 19. Qh3 Qc7 20. Rg4 cxd4 21. Rh4 Qe5+ 22. Kf1 Ne3+ 23. fxe3
Qf5+ 24. Qxf5 gxf5 25. Bh6 Kh7 26. Bg7+ Kg6 27. Rh6+ Kg5 28. Nf3+ Kg4 29. Ne5+
Kg5 30. h4# {Of course there were many alternatives for Black, but White's
attack does look very promising.}) 14. Qh4 Nd7 15. Rd1 (15. Qh6 {
draws by repetition after} Nxf6 16. Qh4 Kg7 17. Qh6+) 15... dxc4 {In order to
prevent Rd3-Rh3, which just as in the 13... Na6 variation is White's main idea.
} 16. dxc5 {Threatening Rxd7 followed by Qh6.} Qc7 (16... Bd5 17. c6) 17. Ne2 (
17. Rxd7 {looks winning but...} Qe5+ 18. Kf1 Qe4 {threatens both 19...Qxh4 and
19...Bg2 mate. I thought that Black was winning but Rybka says it is not so
clear after} 19. Qh3 Rfd8 20. f3) 17... Ne5 (17... Qe5 {loses to} 18. f4 (18.
Rxd7 Bf3) 18... Qf5 19. Rxd7) 18. Qh6 Nf3+ 19. Kf1 Nxh2+ 20. Kg1 Nf3+ 21. Kxh1
{White is still playing for the win.} Qh2+ 22. Qxh2 Nxh2 23. Kxh2 Rfd8 (23...
bxc5 24. Bh6 {White's idea is simply Rh1, Bg7, Kg2 and mate. If Black tries to
prevent this with ...Rd8-d5 then simply Ng3.}) 24. Rh1 (24. Re1 {
looks more normal but White was still playing for mate.}) 24... Rd5 25. f4 Rd2
(25... bxc5 {is also possible:} 26. Ng3 Rad8 27. Ne4 ({
White has to forget about mating ideas:} 27. Kh3 Rd1 28. Rh2 R8d2) (27. Kg2
Rd2+ 28. Kf3 R8d3+ 29. Kg4 Rxc3 30. Bh6 Rg2 31. Rh3 Rxa3 32. Bg7 Raxg3+ 33.
Rxg3 Rxg3+ 34. Kxg3) 27... Rd1 28. Bh4 Rxh1+ 29. Kxh1 Rd1+ 30. Kg2 Ra1 31. Bf2
Rxa3 32. Bxc5) 26. Kg3 Rxe2 27. Bh6 Rd8 28. c6 (28. Bg7 Rd3+ 29. Kg4 (29. Kh4
bxc5) 29... Rg2+ 30. Kh4 bxc5 {and Black is totally winning.}) 28... Rd3+ 29.
Kh4 Rg2 (29... g5+ 30. Kh5 {
Black can no longer prevent both the mating idea and c7-c8Q.}) 30. c7 Rdg3 31.
c8=Q+ Kh7 {White is now a queen up and Black is only threatening draw by
perpetual check, but in this case the threat is as good as its execution...}
32. Qb7 Rg4+ 33. Kh3 R4g3+ 34. Kh4 {Draw agreed.} 1/2-1/2
|
|
|
en effet merci pour la référence sur exactement le même thème !
J'ai regardé juste en faisant défiler les coups ... est-ce que comme dans la variante "trouvée" par leela ci-dessus les blancs peuvent prétendre au même type d'avantage après le sacrifice dans ta partie
|
|
|
@palm6174 : Bon... la dame coincée par les deux fous, cela relève de l'école d'échecs des poussins... Pas nécessaire d'avoir un ( super ) ordi pour ça. Pour un joueur de Nimzo ( ou de Française, par exemple, ce n'est même pas une question de calcul ou de connaisssance, c'est complètement intégré dans ses gènes ! )
Bogoljubov,E - Unknown [C10]
Berlin, 1931
1.e4 e6 2.d4 d5 3.Nc3 dxe4 4.Nxe4 Nf6 5.Nxf6+ Qxf6 6.Bd3 Bd7 7.Nf3 Bc6 8.Bg5 Bxf3 9.Qd2 1-0
Par exemple...
|
|
|
Un autre truc amusant au sujet de leela :
Quand l'évaluation de la position par un moteur "classique" augmente brutalement, c'est en général qu'il a trouvé un gain "tactique", ou en tout cas une combinaison permettant d'être mieux à long terme.
Quand l'évaluation de leela augmente brutalement, c'est plutôt qu'elle a trouvé un gain "stratégique". Il s'agit souvent de coups de pions, mais pas forcément de rupture, plutôt des coups qui ferment la position ou qui menacent de la fermer pour la gagner à long terme.
|
|
|
Coucou
Actuellement Leela fait un très bon score face au derniere version de Stockfish.
Je ne suis pas assez callé à propos de Leela et tout mais je peux vous renvoyer vers une video qui explique en partie son processus et son installation en Moteur Engine
https://www.youtube.com/watch?v=T2SB4Z-o5ZQ
Si des amateurs ou des pros peuvent nous éclairer sur son fonctionnement avec des termes precis, ça serait top
|
|
|
Salut,
Leela tire sa force de la (ou les) carte graphique !
Contrairement aux programmes classiques (Stockfish, Houdini, etc ...) qui utilisent le processeur, Leela obtient de biens meilleurs résultats en utilisant le processeur graphique(GPU) de la carte graphique.
La bonne "combo" est une carte graphique NVIDIA récente (ou plusieurs) associée à CUDA (cela permet à ton GPU de faire des calculs comme ton processeur).
Si tu n'utilises que le processeur comme avec Stockfish, ça marche mais Leela n'est pas compétitive et se fait "manger" par Stockfish.
Je ne sais pas si c'est le genre de réponses que tu attendais :-D
|
|
|
Est-ce que Leela est téléchargeable et utilisable facilement pour un béotien (comme stockfish) ?
Quels sont les avantages/inconvénients par rapport à Fat Fritz ?
Merci pour vos réponses !
|
|
|
Leela a essaye de comprendre la methode de Philippe1234 .... et depuis a arrete les echecs :P
|
|
|
@Docteur pipo : la page https://github.com/LeelaChessZero/lc0/wiki/Getting-Started (anglais) donne les indications pour l'installation (pour l'utilisation, une fois installé, ça fonctionne comme les autres programmes. Je l'utilise dans Fritz UI). Basiquement il faut installer lc0.exe et un fichier weight (le réseau de neurone) (le client.exe n'est pas important sauf si on veut contribuer à améliorer LC0) et ensuite charger lc0 comme n'importe quel autre engine dans l'UI.
A noter que
1) il est très fortement conseillé d'avoir une carte graphique Nvidia supportant CUDA sinon les performances sont faibles.
2) si tu as 2 cartes graphiques comme mon portable (chipset intégré intel + nvidia), tu risques d'avoir des problèmes de configuration.
3) je n'ai toujours pas réussi à trouver une config qui exploite ma carte graphique nvidia à + de 20% (quand on regarde dans le moniteur de ressource), résultat je dépasse péniblement les 1000 nœuds (max, je suis plus souvent dans les 500) par seconde quand on est censé atteindre 60 000 nœuds avec une bonne carte (la mienne doit avoir 4 ans et je suis sur PC portable).
4) tout aide sur la config est bienvenue
|
|
|
Atha : Pour répondre au point numéro 3.
--> Lorsque tu fais tourner le client de partage de calcule, regardes dans ton gestionnaire de tache
( clique droit / gestionnaire de taches / perfomance/ GPU ) .
Tu devrais voir 4 rectangles avec des petites fleches au dessus de celle-ci, cliques dessus et selectionnes compute_0 (ou CUDA pour les GPU récents)
Cela te montrera que ta GPU ( carte graphique ) tournes bien à fond.
|
|
|
atha et Rmx8: merci pour ces indications !
|
|
|
@chemtov
"Quand j'ai les Blancs, je gagne parce que j'ai les Blancs, quand j'ai les Noirs, je gagne parce que je m'appelle Bogolyoubov”. Bogolyoubov ☻
|
|
|
J'ai trouvé tout ce fil vraiment intéressant. Pour ma part , je ne suis pas sûr que les programmes d'echecs sur PC actuels avec des processeurs intel ou AMD de derniere generation et jouant à 3000 elo soient beaucoup plus intelligemment écrits en langage informatique type Leila ou autre que ne l'étaient les antiques logiciels d'echecs qui tounaient sur les petites machines dediees mephisto ou Fidelity il y a 40 ans...et qui "pesaient" quelques dizaines de kilooctets et tournaient sur des microprocesseurs moins puissants que ceux sur mon micro-onde d'aujourd'hui.
A mon idée ce sont surtout les ordinateurs qui ont progressé...et beaucoup moins les logiciels même affublés du terme flatteur d'Intelligence Artificielle...
|
|
|
le joli troll, tu voudrais dire que les methodes de programmation sont les memes entre les années 80 et l'epoque actuelle ???
mais que font nos chercheurs ????
hahahahaha
|
|
|
Il me semble pour le coup qu'il y a eu une vraie révolution sur la programmation des logiciels d'Echecs, et un bond sur leur performance (ils ont pris 200 points Elo en peu de temps) il y a une dizaine d'années.
Ce n'est pas qu'une histoire de processeurs.
|
|
|
la 18eme saison de TCEC a démarré hier, et 8 parties ont déjà été jouée entre Leela et Stockfish 11.
déjà 50% de parties décisives, et Stockfish mène pour le moment 3 - 1 et est gagnant dans la 9ème.
|
|
|


